Introduction générale
Bienvenue dans cette formation dédiée aux Transformers, une technologie qui a révolutionné le domaine de l'intelligence artificielle.
Cette formation s'adresse spécifiquement à un public non technicien qui souhaite comprendre ce que sont les Transformers, comment ils fonctionnent, pourquoi ils sont si importants dans le paysage actuel de l'IA, et ce que nous réserve l'avenir dans ce domaine.
Au cours de cette formation, nous allons démystifier cette technologie complexe en utilisant des explications simples, des analogies concrètes et des exemples du monde réel. Vous n'avez pas besoin de connaissances préalables en programmation ou en mathématiques pour suivre cette formation.
Nous commencerons par découvrir l'histoire des Transformers et comment ils ont émergé dans le paysage de l'IA. Nous explorerons ensuite leur impact révolutionnaire sur différents domaines, avant de plonger dans leur fonctionnement de manière accessible. Nous examinerons leurs forces et avantages, et terminerons par un regard vers l'avenir de cette technologie.
À la fin de cette formation, vous aurez une compréhension claire de ce que sont les Transformers, de leur importance dans le monde actuel, et de leur potentiel futur.
Module 1 : Découverte des Transformers
1.1 Qu'est-ce qu'un Transformer ?
Un Transformer est une architecture d'intelligence artificielle spécialement conçue pour comprendre et générer du langage humain, ainsi que pour traiter d'autres types de données séquentielles. Imaginez-le comme un système très sophistiqué capable de saisir le sens des mots, des phrases et même des documents entiers, tout en comprenant les relations complexes entre les différents éléments.
Dans l'écosystème de l'IA, les Transformers occupent aujourd'hui une place centrale. Ils sont à la base des modèles les plus avancés comme GPT (qui alimente ChatGPT), BERT (utilisé par Google pour améliorer ses recherches), ou encore DALL-E (qui génère des images à partir de descriptions textuelles).
Mais pourquoi ce nom "Transformer" ? Contrairement à ce que l'on pourrait penser, il ne fait pas référence aux robots de science-fiction qui se transforment. Le nom vient plutôt de la capacité de ces modèles à transformer une séquence d'entrée (comme une phrase dans une langue) en une autre séquence (comme la même phrase dans une autre langue). Cette transformation s'effectue en comprenant profondément le contexte et les relations entre les éléments de la séquence.
1.2 L'histoire des Transformers
Avant l'arrivée des Transformers, le traitement du langage naturel reposait principalement sur des architectures comme les réseaux de neurones récurrents (RNN) et les réseaux de neurones convolutifs (CNN). Ces modèles, bien qu'efficaces pour certaines tâches, présentaient des limitations importantes, notamment dans leur capacité à traiter des séquences longues et à capturer des relations distantes entre les mots.
Le tournant décisif est survenu en juin 2017 avec la publication de l'article "Attention is All You Need" par une équipe de chercheurs de Google Brain, composée d'Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser et Illia Polosukhin. Cet article a introduit l'architecture Transformer, qui a révolutionné le domaine du traitement du langage naturel.
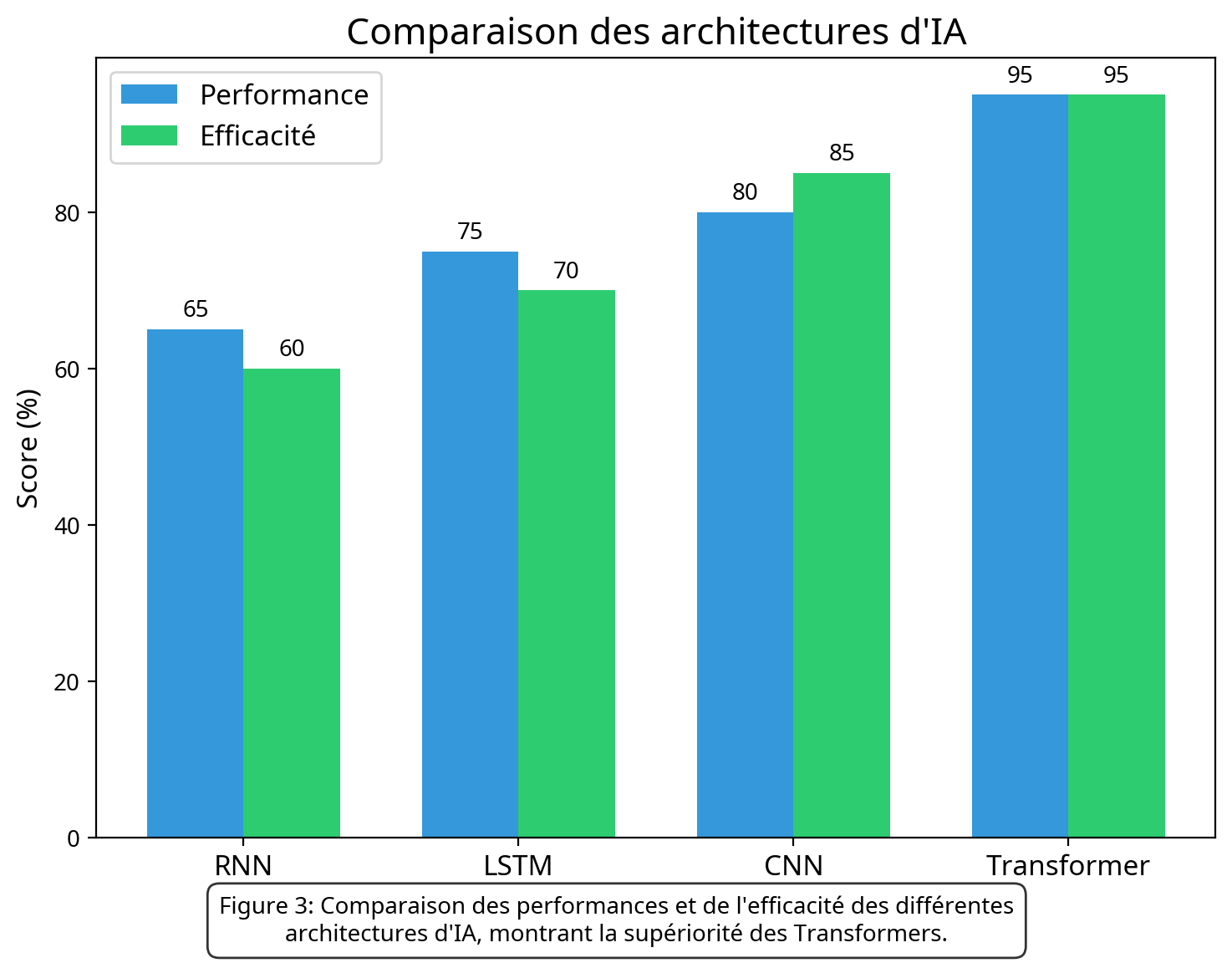
Figure 1: Comparaison des performances et de l'efficacité des différentes architectures d'IA, montrant la supériorité des Transformers.
L'innovation majeure des Transformers réside dans leur mécanisme d'attention, qui permet au modèle de "prêter attention" à différentes parties d'une séquence d'entrée lors du traitement de chaque élément. Cette approche a permis de surmonter les limitations des architectures précédentes et d'obtenir des performances nettement supérieures sur diverses tâches linguistiques.
Suite à cette publication, plusieurs modèles basés sur l'architecture Transformer ont vu le jour :
- BERT (Bidirectional Encoder Representations from Transformers), développé par Google en 2018, qui a amélioré significativement la compréhension du langage naturel.
- GPT (Generative Pre-trained Transformer), développé par OpenAI, dont les versions successives (GPT-2, GPT-3, GPT-4) ont montré des capacités de plus en plus impressionnantes en génération de texte.
- T5 (Text-to-Text Transfer Transformer), qui a unifié différentes tâches de traitement du langage naturel dans un cadre commun.
Ces modèles ont rapidement établi de nouveaux standards de performance dans le domaine du traitement du langage naturel, surpassant les approches précédentes sur pratiquement toutes les tâches.
Module 2 : La révolution des Transformers dans l'IA
2.1 L'impact sur le traitement du langage naturel
Les Transformers ont complètement transformé le domaine du traitement du langage naturel (NLP), en apportant des avancées majeures dans plusieurs domaines clés.
En traduction automatique, les Transformers ont permis des progrès spectaculaires. Avant leur arrivée, la traduction automatique produisait souvent des résultats approximatifs qui nécessitaient des corrections humaines substantielles. Aujourd'hui, des systèmes comme DeepL ou Google Translate, qui s'appuient sur des architectures Transformer, offrent des traductions d'une qualité remarquable, capables de préserver les nuances et le style du texte original.
La compréhension du langage humain a également fait un bond en avant. Les modèles basés sur les Transformers peuvent désormais :
- Comprendre le contexte et les nuances d'une phrase
- Saisir les références implicites et les anaphores
- Interpréter correctement les ambiguïtés linguistiques
- Reconnaître les sentiments et les émotions exprimés dans un texte
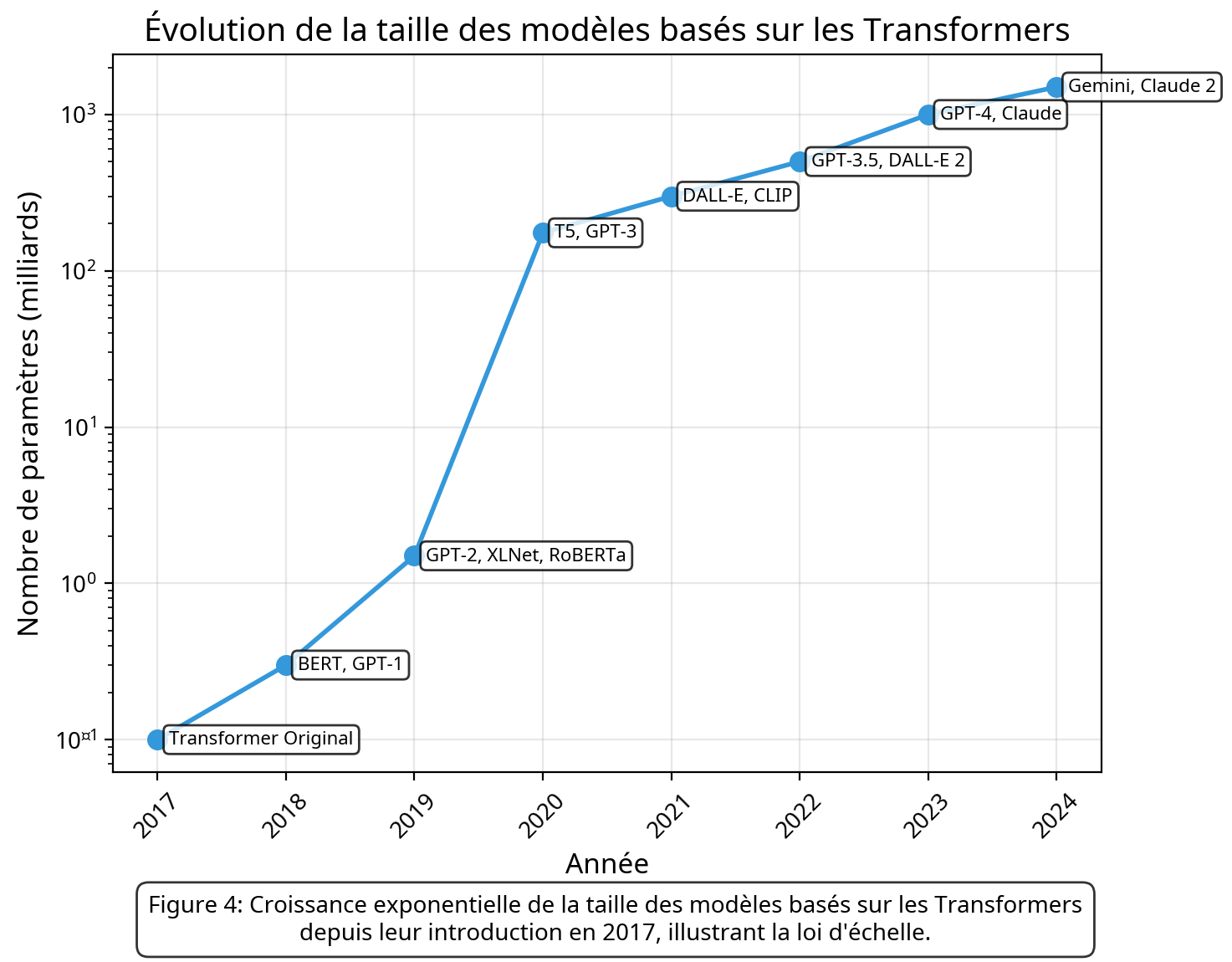
Figure 2: Croissance exponentielle de la taille des modèles basés sur les Transformers depuis leur introduction en 2017, illustrant la loi d'échelle.
Parmi les modèles emblématiques qui ont marqué cette révolution, on peut citer :
- BERT, qui a transformé la recherche d'information en comprenant mieux les requêtes des utilisateurs. Google l'a intégré à son moteur de recherche en 2019, améliorant significativement la pertinence des résultats.
- GPT et ses successeurs, qui ont démontré des capacités impressionnantes en génération de texte, au point de produire des contenus difficiles à distinguer de ceux écrits par des humains.
- RoBERTa, XLNet, ALBERT et d'autres variantes qui ont continué à repousser les limites de la performance sur diverses tâches linguistiques.
Ces modèles ont non seulement amélioré les performances techniques, mais ils ont aussi rendu les technologies de traitement du langage plus accessibles et plus utiles pour le grand public.
2.2 Au-delà du langage
Bien que les Transformers aient été initialement conçus pour le traitement du langage, leur architecture flexible s'est avérée remarquablement adaptable à d'autres types de données et domaines.
Dans le domaine de la vision par ordinateur, les Vision Transformers (ViT) ont démontré qu'il était possible d'appliquer l'architecture Transformer aux images avec d'excellents résultats. En traitant une image comme une séquence de patches, ces modèles peuvent capturer des relations spatiales complexes et atteindre des performances comparables ou supérieures aux réseaux convolutifs traditionnels sur des tâches comme la classification d'images, la détection d'objets ou la segmentation sémantique.
Les Transformers ont également trouvé des applications dans des domaines scientifiques comme :
- La biologie, où des modèles comme AlphaFold 2 de DeepMind utilisent des architectures basées sur les Transformers pour prédire la structure tridimensionnelle des protéines avec une précision sans précédent, résolvant ainsi un problème vieux de 50 ans.
- La chimie, où les Transformers aident à prédire les propriétés des molécules et à accélérer la découverte de nouveaux médicaments.
- La physique, où ils contribuent à l'analyse de données complexes issues d'expériences scientifiques.
L'une des évolutions les plus prometteuses concerne les modèles multimodaux, capables de traiter simultanément différents types de données (texte, images, audio, etc.). Des modèles comme CLIP d'OpenAI peuvent comprendre les relations entre les images et leur description textuelle, ouvrant la voie à des applications comme la recherche d'images par description naturelle ou la génération d'images à partir de texte.
2.3 L'IA générative et les Transformers
L'IA générative, qui désigne la capacité des systèmes d'IA à créer du contenu original, a connu une véritable explosion grâce aux Transformers. Cette révolution a transformé notre rapport à la technologie et ouvert des possibilités créatives sans précédent.
Les Transformers ont rendu possible l'IA générative moderne grâce à plusieurs caractéristiques clés :
- Leur capacité à capturer des dépendances à longue distance dans les données
- Leur aptitude à apprendre des représentations contextuelles riches
- Leur architecture scalable qui permet d'entraîner des modèles de plus en plus grands
- Leur flexibilité qui les rend adaptables à différents types de contenu
ChatGPT et d'autres assistants conversationnels basés sur les Transformers ont démocratisé l'accès à l'IA générative. Ces systèmes peuvent :
- Engager des conversations naturelles et fluides
- Répondre à des questions complexes
- Aider à la rédaction et à l'édition de textes
- Expliquer des concepts difficiles de manière accessible
- Générer du code informatique fonctionnel
Au-delà du texte, les Transformers ont également révolutionné d'autres domaines créatifs :
- La génération d'images avec des modèles comme DALL-E, Midjourney ou Stable Diffusion, qui peuvent créer des visuels impressionnants à partir de descriptions textuelles
- La création musicale, où des modèles comme MusicLM de Google peuvent composer des morceaux originaux dans différents styles
- La génération de vidéos, un domaine en pleine expansion avec des modèles comme Sora d'OpenAI
Cette démocratisation de la création assistée par IA soulève des questions importantes sur l'avenir de la créativité humaine, les droits d'auteur et l'authenticité du contenu, mais elle ouvre également des possibilités passionnantes pour amplifier la créativité humaine et rendre la production de contenu plus accessible.
Module 3 : Comment fonctionnent les Transformers ?
3.1 Les principes fondamentaux
Pour comprendre le fonctionnement des Transformers sans entrer dans les détails techniques complexes, nous pouvons nous appuyer sur quelques principes fondamentaux et des analogies accessibles.
L'architecture générale d'un Transformer est composée de deux parties principales :
- L'encodeur, qui traite les données d'entrée et les transforme en une représentation riche en informations
- Le décodeur, qui utilise cette représentation pour générer une sortie
Imaginons une traduction du français vers l'anglais : l'encodeur "comprend" la phrase française, tandis que le décodeur "génère" la traduction anglaise. Certains modèles n'utilisent que l'encodeur (comme BERT) ou que le décodeur (comme GPT), selon leur objectif.
Une caractéristique révolutionnaire des Transformers est leur capacité à traiter les données en parallèle plutôt que séquentiellement. Pour illustrer cette différence :
- Les modèles précédents (RNN) fonctionnaient comme une personne lisant un livre mot après mot, devant se souvenir de ce qu'elle a lu précédemment
- Les Transformers fonctionnent plutôt comme un groupe de personnes, chacune lisant un mot différent simultanément, puis partageant leurs observations pour comprendre l'ensemble du texte
Cette approche parallèle présente deux avantages majeurs :
- Elle est beaucoup plus rapide, permettant de traiter de grandes quantités de données efficacement
- Elle permet de mieux capturer les relations entre des éléments éloignés dans une séquence
Pour simplifier encore, on peut comparer un Transformer à un chef d'orchestre qui, au lieu d'écouter chaque musicien l'un après l'autre, les entend tous simultanément et comprend parfaitement comment leurs parties s'harmonisent pour former une symphonie cohérente.
3.2 Le mécanisme d'attention
Le mécanisme d'attention est le cœur des Transformers, leur innovation la plus importante. Mais qu'est-ce que l'attention en IA exactement ?
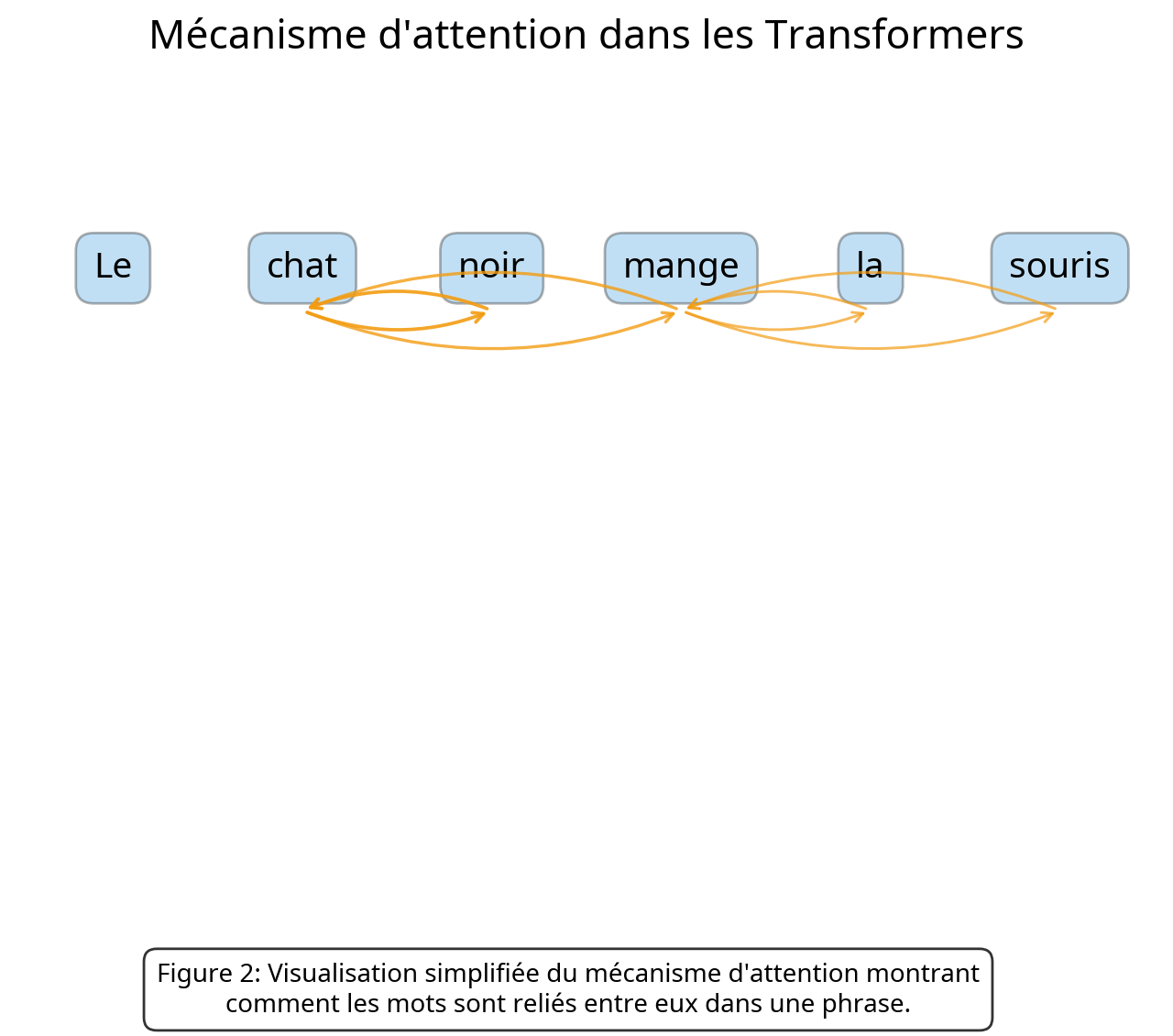
Figure 3: Visualisation simplifiée du mécanisme d'attention montrant comment les mots sont reliés entre eux dans une phrase.
L'attention en IA imite la façon dont nous, humains, prêtons attention à certains éléments plus qu'à d'autres lorsque nous traitons l'information. Lorsque vous lisez une phrase, votre cerveau établit automatiquement des connexions entre différents mots pour comprendre le sens global. Par exemple, dans la phrase "Le chat qui a mangé la souris était noir", vous comprenez que "noir" se réfère au "chat" et non à la "souris", même si "souris" est plus proche de "noir" dans la phrase.
Les Transformers font quelque chose de similaire grâce au mécanisme d'attention. Pour chaque mot d'une séquence, le modèle calcule des "scores d'attention" qui indiquent l'importance de chaque autre mot pour comprendre le mot actuel. Ces scores permettent au modèle de se concentrer sur les parties les plus pertinentes de la séquence.
Prenons un exemple concret : dans la phrase "Jean a prêté son livre à Marie parce qu'elle adore lire", le mécanisme d'attention permettra au modèle de comprendre que "elle" se réfère à "Marie" et non à "Jean" ou au "livre". Pour ce faire, il attribuera un score d'attention élevé entre "elle" et "Marie".
Cette capacité est particulièrement importante pour :
- Résoudre les ambiguïtés linguistiques
- Comprendre les références pronominales
- Saisir les relations à longue distance dans un texte
- Capturer le contexte global d'une phrase ou d'un document
L'attention permet ainsi aux Transformers d'avoir une compréhension beaucoup plus nuancée et contextuelle du langage que les modèles précédents, qui avaient tendance à "oublier" les informations distantes.
3.3 Les autres composants clés
Au-delà du mécanisme d'attention, plusieurs autres composants clés contribuent à la puissance des Transformers.
L'encodage positionnel est un élément crucial qui permet aux Transformers de comprendre l'ordre des mots dans une séquence. Puisque les Transformers traitent tous les mots simultanément (contrairement aux modèles séquentiels), ils ont besoin d'un moyen de savoir quelle est la position de chaque mot.
Pour illustrer l'importance de cet encodage, considérons ces deux phrases :
- "Le chat mange la souris"
- "La souris mange le chat"
Ces phrases contiennent exactement les mêmes mots, mais dans un ordre différent, ce qui change complètement leur signification. L'encodage positionnel permet au Transformer de distinguer ces deux phrases en ajoutant une information de position à chaque mot.
L'architecture en couches multiples est un autre aspect fondamental des Transformers. Ces modèles sont composés de plusieurs couches identiques empilées les unes sur les autres, chacune affinant la compréhension du modèle :
- Les premières couches captent des relations simples entre les mots, comme les associations basiques
- Les couches intermédiaires identifient des structures grammaticales et syntaxiques plus complexes
- Les couches supérieures comprennent des concepts abstraits et des relations sémantiques sophistiquées
Cette organisation en couches permet une compréhension progressive et de plus en plus profonde du contenu traité.
Enfin, l'attention multi-têtes est une extension du mécanisme d'attention qui permet au modèle d'examiner une séquence sous différents angles simultanément. C'est comme si plusieurs personnes lisaient le même texte, chacune se concentrant sur un aspect différent :
- Une personne se concentre sur les relations grammaticales
- Une autre sur le ton émotionnel
- Une troisième sur les références temporelles
- Et ainsi de suite...
En combinant ces différentes "têtes d'attention", le modèle obtient une compréhension beaucoup plus riche et complète du texte, capable de capturer différentes nuances et dimensions du langage.
Module 4 : Les forces des Transformers
4.1 Pourquoi les Transformers sont si puissants
Les Transformers ont rapidement surpassé les architectures précédentes grâce à plusieurs avantages fondamentaux qui leur confèrent une puissance exceptionnelle.
La parallélisation et l'efficacité computationnelle constituent l'un des atouts majeurs des Transformers. Contrairement aux réseaux récurrents (RNN) qui traitent les données séquentiellement, les Transformers peuvent traiter tous les éléments d'une séquence simultanément. Cette parallélisation présente plusieurs avantages :
- Des temps d'entraînement considérablement réduits
- Une utilisation optimale des capacités des GPU modernes
- La possibilité de traiter des ensembles de données beaucoup plus volumineux
- L'entraînement de modèles de plus en plus grands et complexes
Cette efficacité a été cruciale pour permettre l'émergence des grands modèles de langage (LLM) comme GPT et BERT, qui n'auraient pas pu être entraînés efficacement avec les architectures précédentes.
La capture des dépendances à longue distance est une autre force majeure des Transformers. Grâce au mécanisme d'attention, ils excellent dans l'établissement de connexions entre des éléments très éloignés dans une séquence :
- Ils peuvent établir des liens entre des mots séparés par de nombreux autres dans un texte
- Ils comprennent mieux les références, les anaphores et les relations complexes
- Ils maintiennent une compréhension cohérente du contexte, même dans de longs documents
Cette capacité permet aux Transformers de produire des résultats beaucoup plus cohérents et contextuellement appropriés que les modèles précédents.
La scalabilité des modèles est un troisième avantage déterminant. Les Transformers ont démontré une capacité remarquable à s'améliorer avec l'augmentation de leur taille et des données d'entraînement. Cette propriété, connue sous le nom de "scaling law" (loi d'échelle), a permis le développement de modèles de plus en plus grands et performants, avec des améliorations continues des capacités à chaque augmentation d'échelle.
4.2 Les avantages pratiques
Au-delà de leurs forces techniques, les Transformers offrent plusieurs avantages pratiques qui ont contribué à leur adoption massive.
La personnalisation rapide et efficace est l'un de ces avantages clés. Les Transformers ont révolutionné la façon dont les modèles d'IA peuvent être adaptés à des tâches spécifiques. Grâce à des techniques comme l'apprentissage par transfert (fine-tuning), des modèles pré-entraînés peuvent être rapidement adaptés à des applications spécifiques avec relativement peu de données et de ressources computationnelles.
Cette approche présente plusieurs bénéfices :
- Elle réduit considérablement le temps et les coûts de développement
- Elle permet à des organisations avec des ressources limitées d'accéder à des technologies d'IA avancées
- Elle facilite l'adaptation des modèles à des domaines spécialisés ou à des langues moins répandues
Les capacités multimodales constituent un autre avantage majeur. Bien que les Transformers aient été initialement conçus pour le traitement du langage, leur architecture flexible s'est avérée remarquablement adaptable à d'autres types de données :
- Traitement d'images (Vision Transformers)
- Analyse de séquences biologiques (comme AlphaFold)
- Traitement de données audio et musicales
- Combinaison de plusieurs modalités (texte et image, par exemple)
Cette polyvalence a considérablement élargi le champ d'application des Transformers, les faisant passer d'outils spécialisés dans le traitement du langage à une architecture fondamentale pour de nombreux domaines de l'IA.
L'architecture flexible et modulaire des Transformers permet également de les adapter à une grande variété de tâches et de contraintes. Les chercheurs et développeurs peuvent modifier le nombre de couches, la taille du modèle, et d'autres paramètres pour trouver le meilleur compromis entre performance et efficacité selon leurs besoins spécifiques.
4.3 Les applications concrètes
Les Transformers ont trouvé des applications dans pratiquement tous les secteurs d'activité, transformant la façon dont les entreprises et les organisations fonctionnent.
Dans le secteur de la santé, les Transformers contribuent à :
- L'analyse de dossiers médicaux pour identifier des tendances et améliorer les diagnostics
- La prédiction de structures protéiques pour accélérer le développement de médicaments
- L'interprétation d'images médicales comme les radiographies ou les IRM
- La génération de résumés de littérature scientifique pour aider les chercheurs
Dans le domaine juridique, ils permettent :
- L'analyse de contrats et de documents légaux
- La recherche de jurisprudence pertinente
- L'automatisation de certaines tâches administratives
- La simplification de textes juridiques complexes
Dans le secteur financier, les applications incluent :
- L'analyse de sentiments sur les marchés financiers
- La détection de fraudes dans les transactions
- L'automatisation du service client
- L'analyse de rapports financiers et de nouvelles économiques
Dans l'éducation, les Transformers sont utilisés pour :
- Créer des tuteurs virtuels personnalisés
- Générer des exercices adaptés au niveau de l'apprenant
- Évaluer automatiquement certains types de travaux
- Rendre l'apprentissage plus accessible aux personnes en situation de handicap
Ces exemples ne représentent qu'une fraction des applications possibles. À mesure que la technologie continue d'évoluer, de nouvelles utilisations émergent constamment, témoignant de la polyvalence et de la puissance des Transformers.
Module 5 : L'avenir des Transformers
5.1 Les limitations actuelles
Malgré leurs performances impressionnantes, les Transformers font face à plusieurs défis importants qui limitent leur utilisation et leur développement.
Le coût computationnel élevé est l'une des limitations les plus significatives. Les Transformers, en particulier les grands modèles, nécessitent d'énormes ressources computationnelles :
- L'entraînement de modèles comme GPT-4 est estimé entre 100 millions et 1 milliard de dollars
- Leur mécanisme d'attention, qui compare chaque élément d'une séquence avec tous les autres, entraîne une complexité quadratique (doubler la longueur d'une séquence quadruple le coût de calcul)
- Le déploiement de ces modèles en production peut coûter des centaines de milliers, voire des millions de dollars par mois
Cette réalité économique limite l'accès à ces technologies aux grandes entreprises et institutions disposant de ressources considérables.
Les limites de contexte constituent une autre contrainte importante. Bien que les Transformers puissent traiter des séquences plus longues que les architectures précédentes, ils sont toujours limités par la taille de leur fenêtre de contexte :
- Les premiers modèles GPT étaient limités à environ 2048 tokens (environ 1500 mots)
- Les versions plus récentes ont étendu cette limite à 8K, 16K ou même 32K tokens
- Mais ces limites restent insuffisantes pour traiter des livres entiers, de longs documents techniques ou des conversations étendues
Au-delà de ces limites, les performances se dégradent et les coûts augmentent de manière prohibitive.
Les barrières d'accès représentent un troisième défi majeur. En raison de leurs exigences en matière de ressources, les Transformers créent une division entre ceux qui peuvent et ceux qui ne peuvent pas accéder à ces technologies :
- Seules les grandes entreprises et institutions peuvent se permettre de développer et déployer des modèles Transformer à grande échelle
- Cette situation limite l'innovation et la diversité dans le domaine de l'IA
- Elle crée également des inégalités géographiques, les régions disposant de moins d'infrastructures technologiques étant désavantagées
Ces limitations ont motivé la recherche d'alternatives plus efficaces et accessibles.
5.2 Les architectures émergentes
Face aux limitations des Transformers, plusieurs architectures alternatives sont en développement, chacune visant à surmonter certains des défis tout en conservant les avantages des Transformers.

Figure 4: Les principales architectures émergentes qui pourraient potentiellement remplacer les Transformers, avec leurs avantages distinctifs.
RWKV (Receptance Weighted Key Value) est l'une des alternatives les plus prometteuses. Cette architecture hybride combine les avantages des réseaux récurrents (RNN) et des Transformers :
- Elle offre une complexité linéaire plutôt que quadratique, la rendant 10 à 100 fois moins coûteuse à exécuter que les Transformers
- Son architecture récurrente nécessite moins de mémoire
- Elle réduit le biais centré sur l'anglais présent dans de nombreux modèles basés sur les Transformers
RetNet (Retentive Network) est une autre architecture émergente conçue pour gérer efficacement les séquences longues :
- Elle excelle dans la conservation du contexte temporel
- Elle permet un traitement parallèle efficace
- Elle ajuste ses paramètres internes au fur et à mesure de l'apprentissage
Mamba, basé sur les modèles d'espace d'état (SSM), se concentre sur le maintien des dépendances à long terme :
- Il filtre les données non pertinentes pour se concentrer sur l'information importante
- Son architecture simplifiée remplace les blocs d'attention complexes par un seul bloc cohérent
- Il est optimisé pour l'efficacité matérielle
D'autres approches comme Hyena et les Linear Transformers visent également à réduire la complexité computationnelle tout en maintenant des performances élevées.
Ces architectures alternatives ne sont pas nécessairement destinées à remplacer complètement les Transformers, mais plutôt à offrir des options plus efficaces pour certains cas d'usage ou contraintes spécifiques.
5.3 Perspectives d'évolution
L'évolution au-delà des Transformers pourrait avoir plusieurs implications importantes pour l'avenir de l'IA et son impact sur la société.
La démocratisation de l'IA est l'une des perspectives les plus prometteuses. Des architectures plus efficaces pourraient réduire considérablement les coûts de développement et de déploiement de l'IA :
- Des startups et des chercheurs indépendants pourraient développer leurs propres modèles avancés
- Des pays en développement pourraient participer plus activement à l'innovation en IA
- Une plus grande diversité d'acteurs pourrait conduire à des applications plus variées et adaptées à différents contextes culturels et sociaux
L'élimination des barrières linguistiques représente une autre évolution potentielle majeure. Les nouvelles architectures pourraient réduire le biais centré sur l'anglais présent dans de nombreux modèles actuels :
- Des modèles véritablement multilingues pourraient émerger, offrant des performances équivalentes dans toutes les langues
- Les langues à faibles ressources pourraient bénéficier d'outils d'IA aussi performants que ceux disponibles pour l'anglais
- Cette évolution pourrait contribuer à préserver la diversité linguistique et culturelle
Les applications en périphérie (Edge Computing) constituent une troisième perspective d'évolution. Des modèles plus efficaces pourraient fonctionner sur des appareils avec des ressources limitées :
- Des applications d'IA avancées pourraient fonctionner directement sur les smartphones, tablettes ou appareils IoT
- Cela réduirait la dépendance aux connexions internet et aux serveurs distants
- La confidentialité des données serait améliorée, les informations restant sur l'appareil de l'utilisateur
- Des régions à faible connectivité pourraient bénéficier d'applications d'IA dans des domaines comme la santé, l'agriculture ou l'éducation
Ces évolutions pourraient transformer profondément le paysage de l'IA, la rendant plus accessible, plus inclusive et plus adaptée à une diversité de contextes et de besoins.
Module 6 : Conclusion et perspectives
6.1 Récapitulatif des points clés
Au cours de cette formation, nous avons exploré en profondeur le monde des Transformers, depuis leur création jusqu'à leur avenir potentiel. Récapitulons les concepts fondamentaux à retenir :
Les Transformers sont une architecture d'IA révolutionnaire introduite en 2017 qui a transformé le traitement du langage naturel et de nombreux autres domaines. Leur innovation principale réside dans le mécanisme d'attention, qui permet au modèle de se concentrer sur les parties les plus pertinentes d'une séquence.
Nous avons vu comment les Transformers ont révolutionné l'IA en :
- Améliorant considérablement les performances en traduction automatique et en compréhension du langage
- S'étendant au-delà du langage vers la vision, la biologie et d'autres domaines
- Rendant possible l'IA générative moderne avec des applications comme ChatGPT, DALL-E et autres
Nous avons exploré leur fonctionnement à travers :
- L'architecture encodeur-décodeur
- Le mécanisme d'attention qui permet de capturer les relations entre les éléments d'une séquence
- L'encodage positionnel qui préserve l'information sur l'ordre des éléments
- L'architecture en couches multiples qui permet une compréhension progressive et de plus en plus profonde
Les forces des Transformers incluent :
- La parallélisation qui permet un traitement efficace des données
- La capacité à capturer des dépendances à longue distance
- La scalabilité qui permet des améliorations continues avec l'augmentation de la taille des modèles
- La flexibilité qui les rend adaptables à diverses tâches et types de données
Enfin, nous avons examiné l'avenir des Transformers, leurs limitations actuelles et les architectures émergentes qui pourraient les compléter ou les remplacer dans certains contextes.
L'importance des Transformers dans l'écosystème de l'IA est difficile à surestimer. Ils ont non seulement établi de nouveaux standards de performance technique, mais ils ont également rendu l'IA plus accessible et utile pour le grand public, transformant notre interaction quotidienne avec la technologie.
6.2 Pour aller plus loin
Si cette formation a éveillé votre curiosité et que vous souhaitez approfondir vos connaissances sur les Transformers et l'IA en général, voici quelques ressources recommandées :
Livres accessibles aux non-techniciens :
- "L'IA expliquée à mon boss" par Luc Julia
- "Le Manifeste des Usages de l'Intelligence Artificielle" par Cécile Dejoux
- "L'Intelligence artificielle n'existe pas" par Luc Julia
Sites web et blogs :
- "AI for Everyone" sur Coursera, un cours en ligne de Andrew Ng spécialement conçu pour les non-techniciens
- Le blog "The Batch" de deeplearning.ai, qui propose des résumés hebdomadaires des avancées en IA dans un langage accessible
- "AI Explained" sur YouTube, qui vulgarise les concepts d'IA avec des animations claires
Communautés et forums :
- Le forum "AI Alignment" qui discute des implications éthiques et sociétales de l'IA
- Le groupe LinkedIn "AI for Good" qui se concentre sur les applications positives de l'IA
- Les meetups locaux sur l'IA, qui offrent souvent des présentations accessibles aux débutants
Outils accessibles aux non-techniciens :
- Hugging Face Spaces, qui permet d'explorer et d'utiliser des modèles d'IA sans programmation
- Elicit.org, un assistant de recherche basé sur l'IA qui aide à explorer la littérature scientifique
- Perplexity.ai, un moteur de recherche augmenté par l'IA qui fournit des réponses détaillées à vos questions
N'oubliez pas que le domaine de l'IA évolue rapidement, et que rester curieux est la meilleure façon de suivre ces développements. Même sans formation technique, vous pouvez comprendre les principes fondamentaux et les implications de ces technologies qui transforment notre monde.
Activités pédagogiques et ressources
Quiz interactif
-
Quel article a introduit l'architecture Transformer en 2017 ?
a) "Deep Learning for NLP"
b) "Attention is All You Need"
c) "The Transformer Revolution"
d) "Neural Machine Translation" -
Quelle est l'innovation principale des Transformers par rapport aux architectures précédentes ?
a) Leur taille
b) Leur mécanisme d'attention
c) Leur vitesse de calcul
d) Leur consommation d'énergie -
Pourquoi l'encodage positionnel est-il important dans les Transformers ?
a) Pour réduire le temps de calcul
b) Pour permettre au modèle de comprendre l'ordre des mots
c) Pour économiser de la mémoire
d) Pour faciliter l'entraînement
Glossaire des termes techniques
Attention : Mécanisme permettant à un modèle de se concentrer sur les parties les plus pertinentes d'une séquence lors du traitement de chaque élément.
Auto-attention (Self-attention) : Forme d'attention où chaque élément d'une séquence prête attention à tous les autres éléments de la même séquence.
BERT (Bidirectional Encoder Representations from Transformers) : Modèle de langage basé sur l'architecture Transformer qui traite le texte de manière bidirectionnelle.
Encodeur : Partie d'un Transformer qui traite les données d'entrée et les transforme en une représentation riche en informations.
Décodeur : Partie d'un Transformer qui utilise la représentation créée par l'encodeur pour générer une sortie.
Fine-tuning : Processus d'adaptation d'un modèle pré-entraîné à une tâche spécifique en l'entraînant sur un ensemble de données plus petit et spécialisé.
GPT (Generative Pre-trained Transformer) : Série de modèles de langage basés sur l'architecture Transformer, conçus pour la génération de texte.
IA générative : Branche de l'IA qui se concentre sur la création de contenu original (texte, images, musique, etc.).
LLM (Large Language Model) : Modèle de langage de grande taille, généralement basé sur l'architecture Transformer, entraîné sur d'énormes quantités de texte.
NLP (Natural Language Processing) : Traitement du langage naturel, domaine de l'IA qui se concentre sur l'interaction entre les ordinateurs et le langage humain.
Token : Unité de base traitée par un modèle de langage, généralement un mot ou une partie de mot.
Transformer : Architecture de réseau neuronal introduite en 2017, caractérisée par son mécanisme d'attention et sa capacité à traiter des séquences en parallèle.
Vision Transformer (ViT) : Adaptation de l'architecture Transformer pour le traitement d'images.